在 NVIDIA RTX GPU 和 DGX Spark 上免费运行 OpenClaw
OpenClaw (以前称为 Clawdbot 和 Moltbot) 是一款常驻于计算机上的“本地优先”AI 智能体。它之所以迅速走红,是因为它融合了多种功能,成为了一个实用的助手。它能记住您的对话并相应地进行自我调整,在本地计算机上持续运行,使用文件和应用中的上下文,并利用新的“skills”(技能) 扩展其功能。
以下是一些热门用例:
- 私人秘书:OpenClaw 可以访问您的收件箱、日历和文件,自主管理您的日程安排。它可以使用您的文件和先前电子邮件的上下文来起草回复邮件,提前发送您要求的提醒,根据日历上的空闲时段安排会议。
- 主动项目管理:OpenClaw 可以通过您使用的电子邮件或即时通讯渠道定期检查项目状态,向您发送状态检查结果,并根据需要跟进/发送提醒
- 研究智能体:利用来自应用的个性化上下文,OpenClaw 可以生成融合互联网搜索结果与文件内容的报告
OpenClaw 由可在本地或云端运行的大语言模型 (LLM) 提供支持。由于 OpenClaw 的始终在线特性,云端 LLM 可能会产生高昂成本。而且这类 LLM 会要求您上传个人数据。
在指南中,我们将展示如何在 NVIDIA RTX GPU 和 DGX Spark 上完全本地运行 OpenClaw 和 LLM,以节省成本并确保数据保持隐私。
NVIDIA RTX GPU 可为此类工作流提供最佳性能,这要归功于 GPU 中可加速 AI 操作的 Tensor Core,以及 CUDA 对运行 OpenClaw 所需的所有工具的加速。DGX Spark 是特别好的选择,因为它设计为持续运行,并且配备 128GB 内存,能够运行更大规模的本地模型,从而提供最佳的准确性和结果。

开始前的重要须知
您应该意识到 AI 智能体存在风险,并谨慎行事以最大限度降低这些风险。访问 OpenClaw 的网站了解更多信息。
此类智能体存在两项主要风险:
- 您的个人信息或文件可能会被泄露或窃取。
- 智能体本身或连接到机器人的工具可能会使您暴露于恶意代码或网络攻击。
没有方法完全防范所有风险,因此请自行承担风险。以下是我们在测试 OpenClaw 时采取的一些措施:
- 在没有个人数据的单独、干净的电脑或虚拟机上运行 OpenClaw。然后复制您希望智能体可以访问的数据。
- 不要允许它访问您的账户。相反,为智能体创建专用账户,并与其共享特定信息或访问权限。
- 谨慎使用您启用的技能,最好仅测试那些已经过社区验证的技能。
- 确保您用来访问 OpenClaw 助手的任何渠道 (例如 Web UI 或即时通讯渠道) 在本地网络或互联网上都无法未经授权访问。
- 如果您的使用场景允许,请限制其互联网访问权限。
上手指南
要在 Windows 上安装 OpenClaw,我们将使用适用于 Linux 的 Windows 子系统 (简称 WSL)。也可以在 Powershell 中原生安装,但由于稳定性不足,开发者并不建议这样做。
如果使用 DGX Spark,可以跳转到第 2 节。
1. 安装适用于 Linux 的 Windows 子系统
如果您已安装 WSL,可以跳转到下一节“安装 OpenClaw”。要安装 WSL (参考链接):
1.1. 按 Windows 键,输入 PowerShell,右键单击结果,然后选择“以管理员身份运行”。
1.2. 粘贴以下命令,然后按 Enter:
wsl --install
1.3. 运行以下命令检查 WSL 是否正确安装,并看到类似于以下屏幕截图的输出:
wsl --version

1.4. 在 Windows 搜索栏中搜索 Powershell,选择“以管理员身份运行”,然后输入以下命令打开 WSL:
wsl
2. 安装 OpenClaw
2.1. 在 WSL 窗口中运行以下命令:
curl -fsSL https://openclaw.ai/install.sh | bash
这将在计算机上安装 OpenClaw 以及所有必需的依赖项。在下载一些必要的软件包后,OpenClaw 将提示一条安全警告:
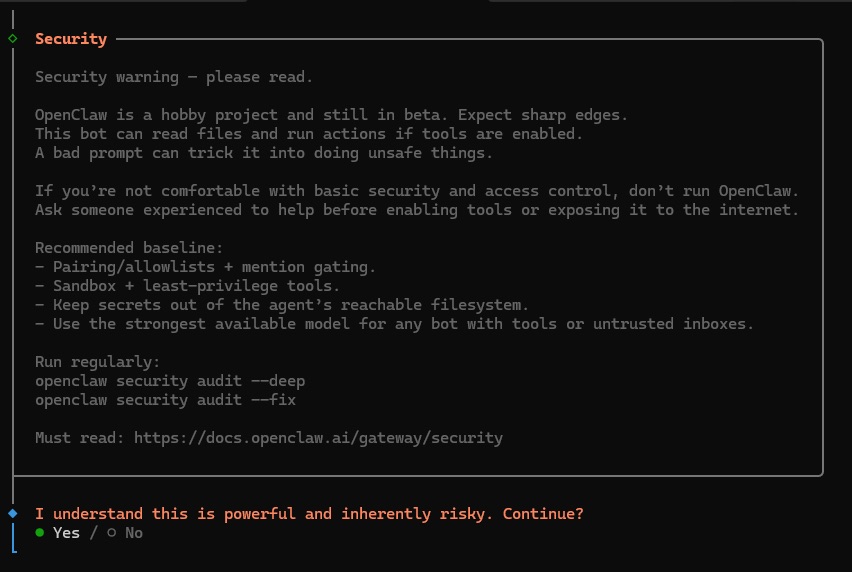
2.2. 请阅读安全风险。如果您同意继续,请使用方向键导航到“Yes”(是) 并按 Enter。
2.3. 继而将被提示选择 Quickstart (快速开始) 或 Manual (手动) 配置模式。选择 Quickstart (快速开始)。

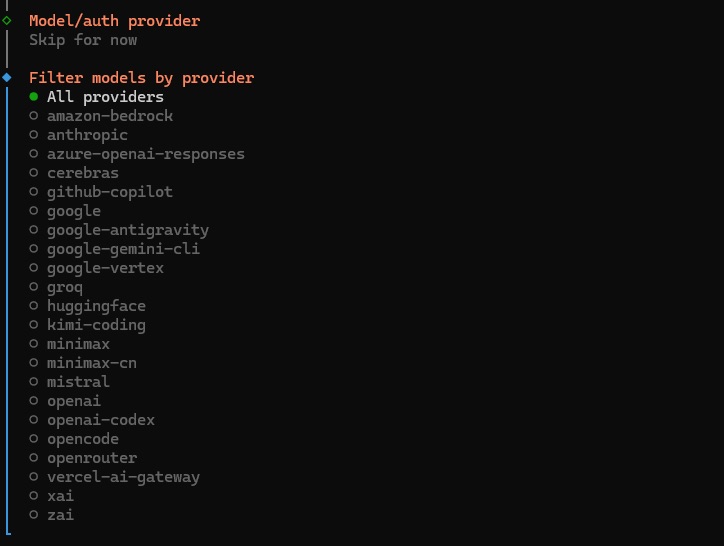
2.4. 将显示用于配置模型提供商的列表。如果希望运行本地模型,请导航到列表最底部,然后选择“Skip for now” (暂时跳过),因为我们稍后会进行配置。如果希望连接云端模型,可以选择一个模型,然后按照指示操作。

2.5. 如果希望连接云端模型,可以选择一个模型,然后按照指示操作。将显示另一个列表提示,用于按提供商筛选模型。选择“All Providers” (所有提供商)。 在随后选择默认模型的提示中,选择“Keep Current” (保持当前)。
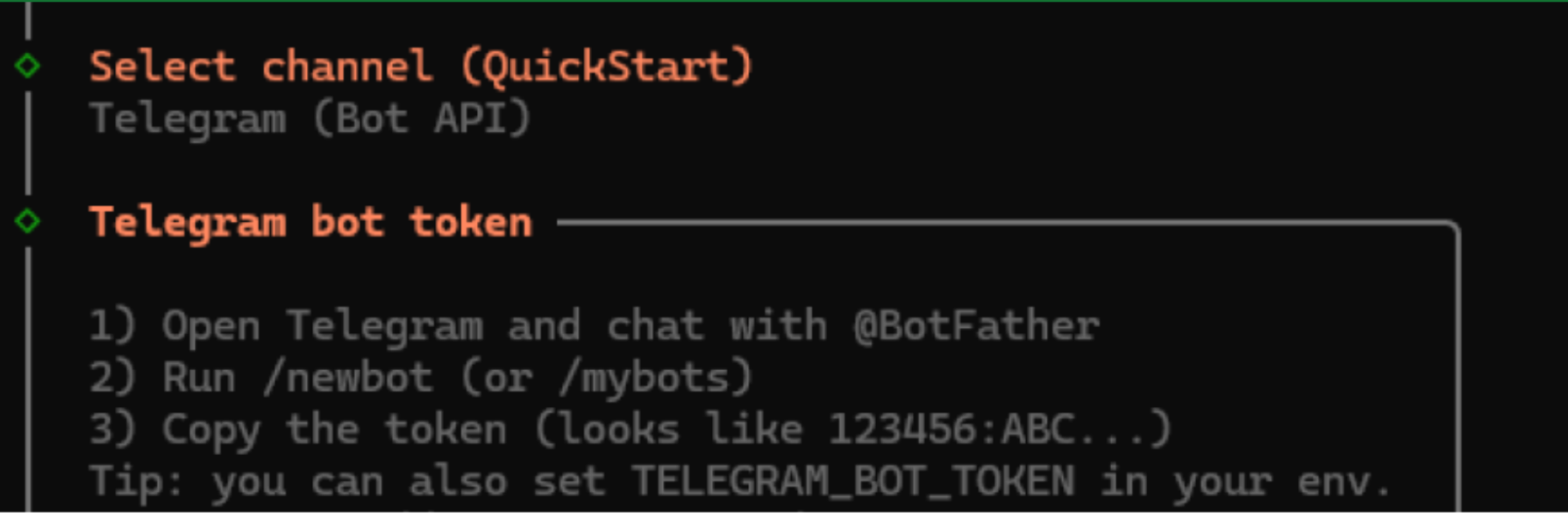
2.6. 将可以连接一个通信渠道,以便在离开电脑时与机器人进行交互。您可以在此选择一种渠道,并按照向导中的步骤完成配置,也可以选择“Skip for Now” (立即跳过),稍后再设置。
■ 例如,如果选择 Telegram,则需要创建一个 Telegram 机器人,为 OpenClaw 提供访问 Token,最后再将 Telegram 聊天中的配对代码提供给 OpenClaw。
2.7. 接下来,系统会提示进行技能配置——这些是机器人将具备的能力。建议先选择“No”(否) 以继续完成设置流程。稍后可以在试验技能并确定用例所需的技能后随时添加相关技能。
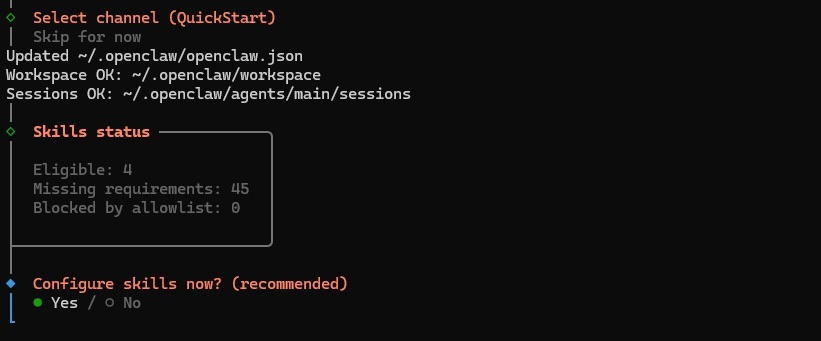
2.8. 下一步,OpenClaw 将提示安装 homebrew 软件包 - 选择“No” (否),Mac 安装需要此软件包,但 Windows 不需要。
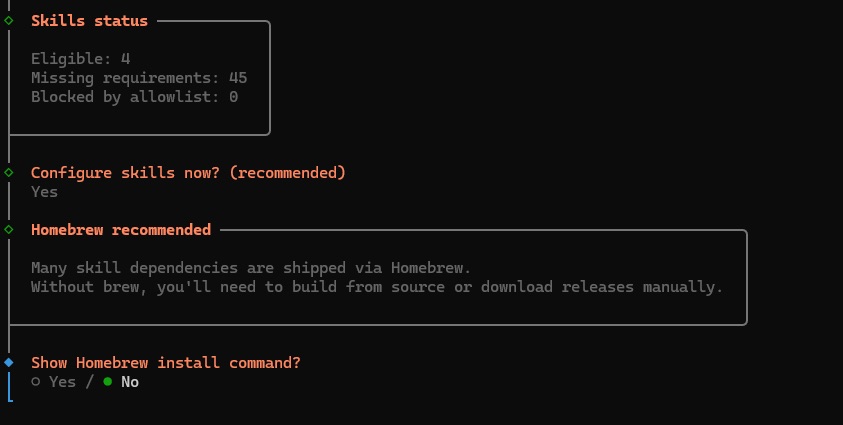
2.9. 下一个提示是安装 Hooks。我们建议选择全部 3 个 Hooks,以获得更好的体验。但请先考虑是否接受数据在本地被记录。
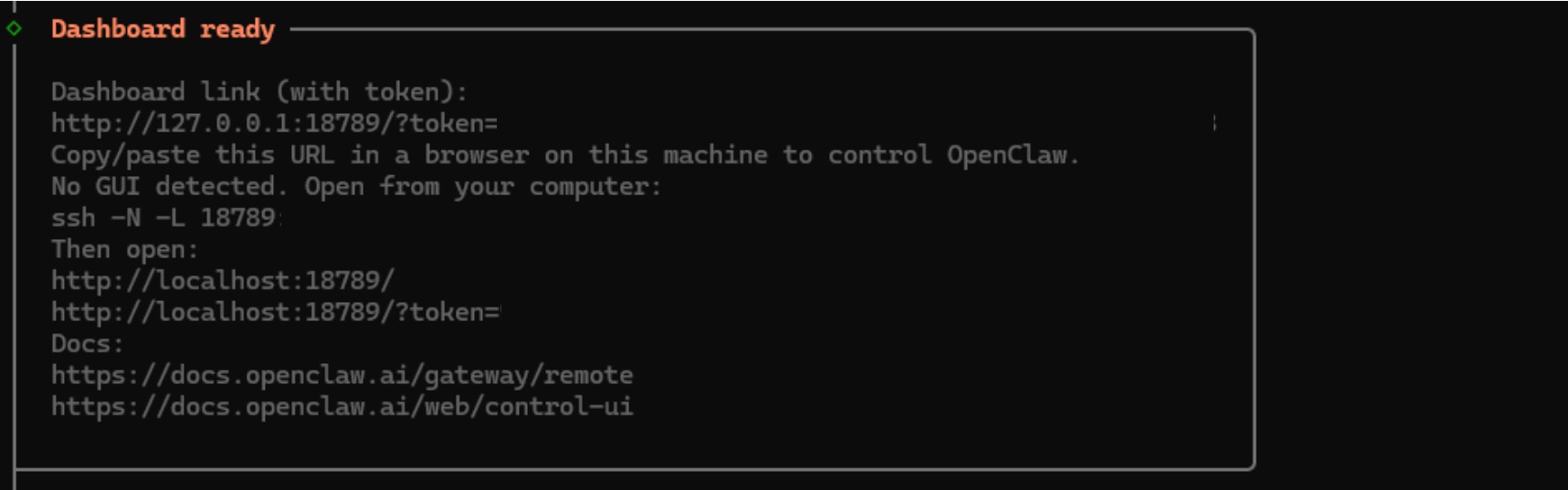
2.10. 生成的终端输出将显示用于访问 OpenClaw 仪表板的 URL。请保存此地址,您将需要它来加载 UI。
2.11. 最后,在最后一个提示中选择“Yes”(是) 以完成 OpenClaw 安装。

2.12. 现在,可以通过提供的访问令牌所对应的仪表板链接来访问OpenClaw了。
3. 本地模型配置
可以使用在 RTX GPU 上本地运行的 LLM 或云端 LLM 来为 OpenClaw 提供动力。在本节中,我们将展示如何将 OpenClaw 配置成使用 LM Studio 或 Ollama 在本地运行。
回答的质量取决于 LLM 的规模和质量。需要确保释放尽可能多的显存 (例如,不要在 GPU 上运行其他工作负载,仅加载所需的技能以最小化上下文等),这样才能使用可充分利用 GPU 的大型 LLM。
3.1. 选择偏好的后端:
■ 如需实现原始性能,推荐使用 LM Studio 作为后端,因为它使用 Llama.cpp 运行 LLM。
■ Ollama 提供了额外的开发者工具来促进部署。
3.2. 如果是在 Windows 下,请在 Windows 搜索栏中搜索 Powershell,选择“以管理员身份运行”,输入以下命令打开另一个 WSL 窗口:(在 DGX Spark 上请跳过此步骤)
wsl
3.3. 下载并安装 LM Studio 或 Ollama:
| LM Studio | Ollama |
curl -fsSL https://lmstudio.ai/install.sh | bash
|
curl -fsSL https://ollama.com/install.sh | sh
|
3.4. 选择您偏好的 LLM:根据您的 GPU 推荐以下模型:
- 6-8GB GPUs:Qwen3.5 4B
- 12-16GB GPUs:Qwen 3.5 9B
- 24-48GB GPUs:Qwen 3.5 27B
- 96-128GB GPUs:Qwen 3.5 122B
3.5. 下载模型:
| LM Studio | Ollama |
lms get openai/gpt-oss-20b
|
ollama pull gpt-oss:20b
|
3.6. 运行模型,并将上下文窗口设置为 32K Token 或更多,这样可以与 OpenClaw 实现良好配合。
| LM Studio | Ollama |
lms load openai/gpt-oss-20b --context-length 32768
|
ollama run gpt-oss:20b /set parameter num_ctx 32768
|
3.7. 配置 OpenClaw 以使用 LM Studio 或 Ollama,并启动网关:
| LM Studio | Ollama |
Navigate to the OpenClaw config file by running:
.explorer
"models": {
|
ollama launch openclaw #If the gateway is already running, it will auto-reload the configuration #You can add "--config" to configure without launching the openclaw gateway yet
|
安装配置完毕!要检查一切是否设置正确,请打开一个浏览器窗口,然后粘贴 OpenClaw URL 和访问令牌。点击新建对话,并试着输入一些内容。如果收到回复,则说明一切就绪!还可以询问 OpenClaw 正在使用哪个模型,甚至可以在网关聊天 UI 中输入 /model MODEL_NAME 来切换模型。
要详细了解如何使用 OpenClaw,请访问 OpenClaw 网站。
您还应该查看适用于 OpenClaw 的 NVIDIA NemoClaw 插件,该插件可为 OpenClaw 启用 NVIDIA 优化插件。访问 NemoClaw 网站了解更多。
对于如何添加新技能,请记住,这会引入额外的风险,所以在添加时务必小心。要添加新技能:
- 让 OpenClaw 配置自身以使用技能
- 使用 webUI 中的侧边栏启用技能
- 在 Clawhub 上查找社区构建的技能
尽情享用龙虾吧!
