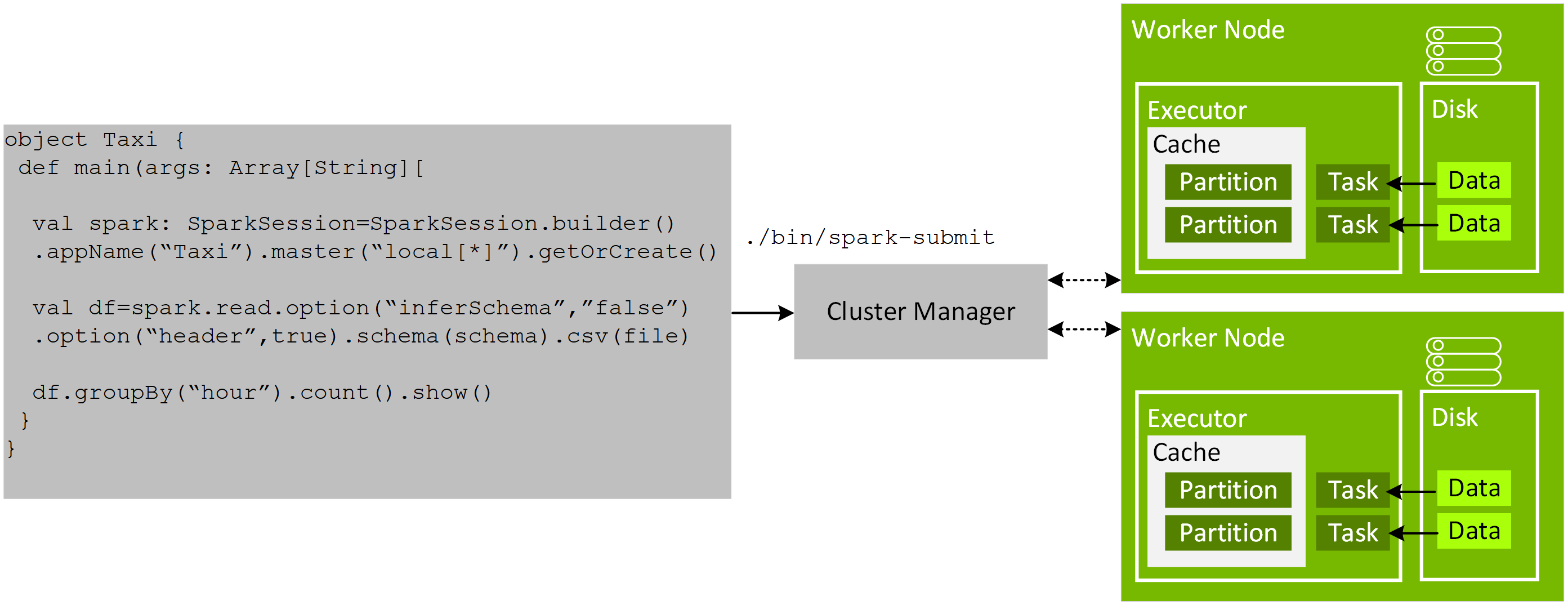
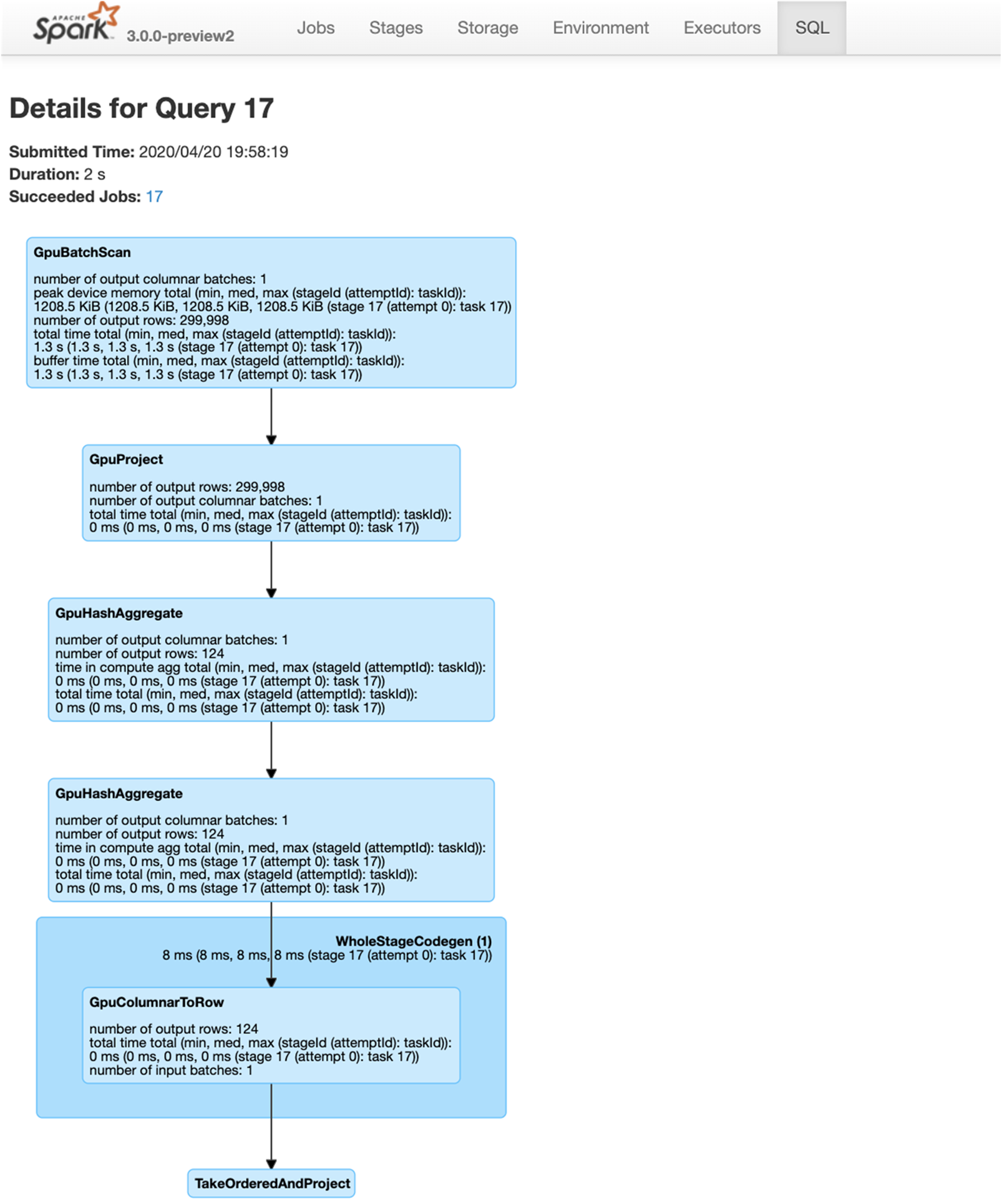
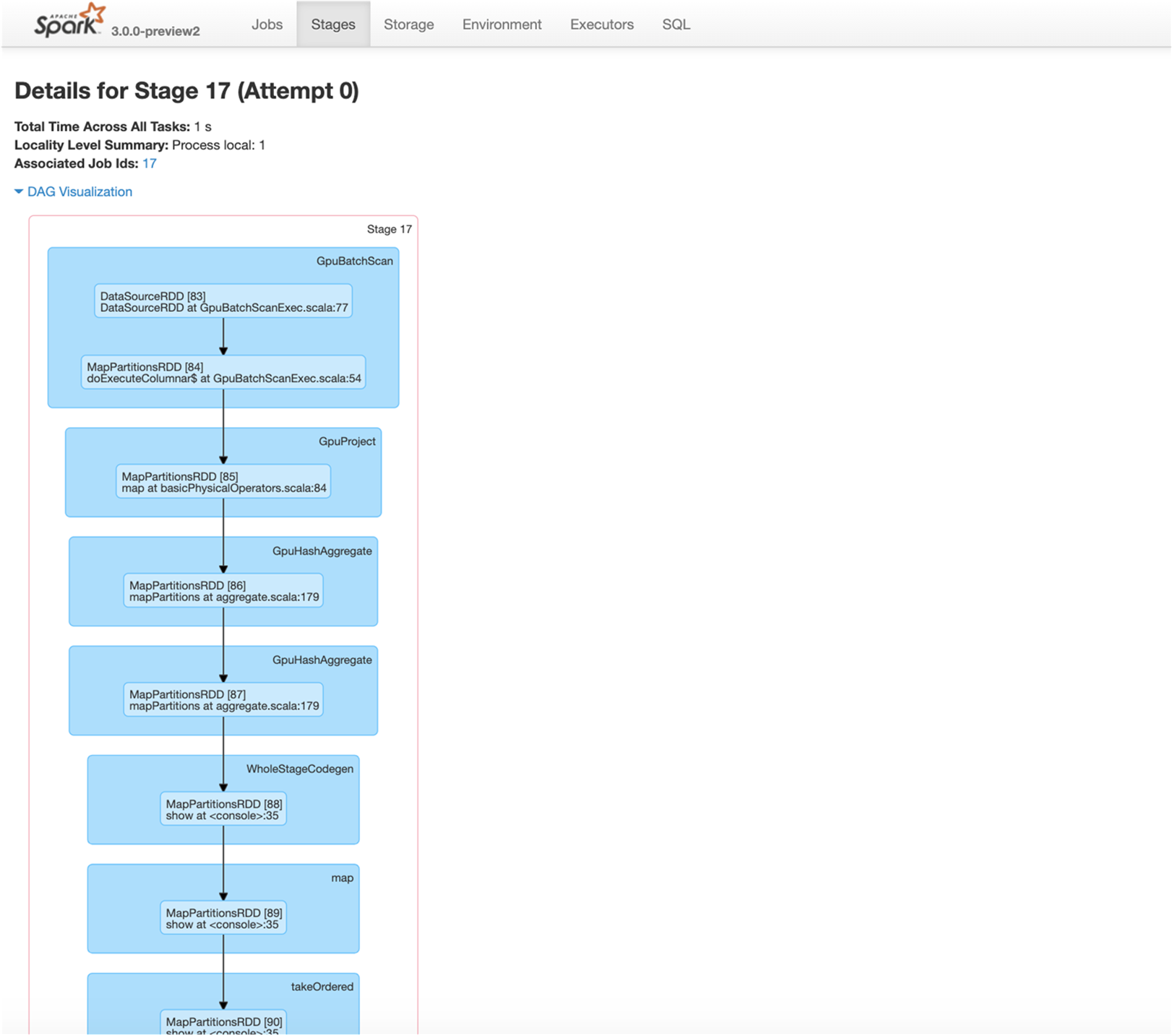
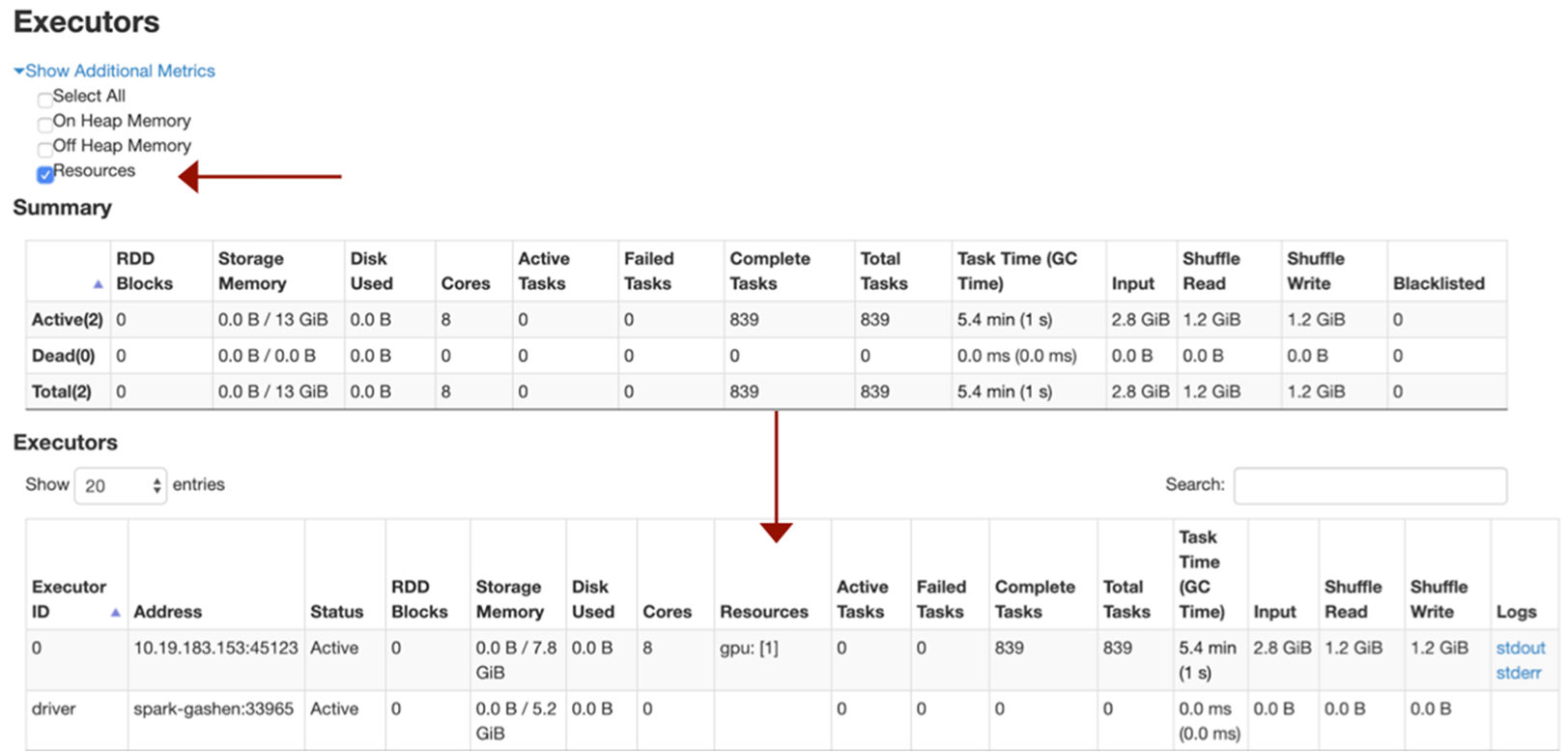
我们在第 3 章讨论了 Spark 3.x 中的 GPU 加速功能。本章将介绍用于 Apache Spark 3 的新 RAPIDS 加速器的使用入门基础知识,以便您利用 GPU 通过 RAPIDS 库加快处理速度(详情请参阅用于 Apache Spark 的 RAPIDS 加速器使用入门)。
用于 Apache Spark 的 RAPIDS 加速器具有以下功能和限制:
- 支持在 GPU 上通过列式处理运行 Spark SQL
- 不需要用户更改 API
- 支持行与列之间的转换处理
- 使用 RAPIDS cuDF 库
- 在 GPU 上运行支持的 SQL 操作,如果未执行某项操作或操作不兼容 GPU,它会回退以使用 Spark CPU 版本。
- 插件无法加速直接操控 RDD 的操作。
- 加速器库还提供了 Spark shuffle 操作的具体实现,该操作可以利用 UCX 优化 GPU 数据传输(尽可能多地将数据保留在 GPU 上,并绕过 CPU 执行 GPU 到 GPU 传输)。
要启用此 GPU 加速功能,您将需要:
- Apache Spark 3.0+
- 配置有 GPU 的 Spark 集群,而且这些 GPU 符合 RAPIDS Dataframe 库 cuDF 的版本要求。
- 每个执行程序一个 GPU。
- 添加以下 jar:
- 与集群上可用的 CUDA 版本相对应的 cudf jar。
- RAPIDS Spark 加速器插件 jar。
- 将配置 spark.plugins 设置为 com.nvidia.spark.SQLPlugin