文本转语音是一种语音合成形式,可将任何文本字符串转换为语音输出。
文本转语音
什么是文本转语音?
将文本低延迟转换为高质量、自然发音的语音,即文本转语音 (TTS),这是数十年来一直颇具挑战性的任务。起初专为具有视觉障碍或阅读障碍的人群而开发,为使其能够聆听书面文字。如今,文本转语音已经发展至各种用例,这些用例以前需要人工操作,或者无法读取,缺乏实用性。其中包括提供驾驶指导、在呼叫中心与客户进行联系,以及为虚拟助理提供动力支持。
常见系统使用实时拼凑的预先录制好的语音元素。近期,神经网络已用于创建完全由机器生成的自然发音的语音。

为何选择文本转语音?
无论是语音闹钟,还是将文本信息转换为语音的汽车助手,或者是 Apple 的 Siri 和亚马逊的 Echo 等复杂的查询和响应系统,文本转语音早已融入到我们的日常生活之中。这解决了看屏幕读取的不实际或不方便等诸多用例问题。
文本转语音正在逐渐深入对话式 AI 领域,这些领域包括自动语音识别 (ASR) 和自然语言处理 (NLP),例如语言之间的翻译。客户服务领域日益发展,语音识别系统能够处理复杂查询,在数据库中搜索答案,还能够通过文本转语音实现响应。现在,电话销售员借助这些系统,使用对话式机器人取代人工呼叫者,这些机器人可以模拟真实对话,无需人工操作员。

研究表明,以类似人类的声音做出响应时,人们会更自在地交流。神经网络使文本转语音系统产生的声音领域得以扩充,而无连接合成的用度或发音合成的复杂性。
文本转语音的工作原理
先进的语音合成模型均以参数神经网络为基础。文本转语音 (TTS) 合成通常分两步完成。
- 第一步,合成网络将文本转换为时间对齐的特征,例如频谱图或基本频率,这些特征是声带在语音中振动的频率。
- 第二步,声码器网络将时间对齐的特征转换为音频波形。

准备用于合成的输入文本需要文本分析,例如将文本转换为单词和句子,识别和扩展缩写以及辨认和分析表达式。表达式包含日期、金额和机场代码。
将文本分析的输出传递到语言分析中,用于改进发音、计算单词的持续时间、破译语音的音期结构,以及理解语法信息。
然后,将语言分析的输出输入到语音合成神经网络模型,例如 Tacotron2,该模型将文本转换为梅尔频谱图,然后输入到 Wave Glow 等神经声码器模型,从而生成自然发音的语音。
热门的 TTS 深度学习模型包括 Wavenet、Tacotron 2 和 WaveGlow。
2006 年,Google WaveNet 引入了深度学习技术,采用一种新方法,一次直接对音频信号的原始波形进行一个样本建模。其模型为概率和自回归,且每个音频样本的预测分布均以所有之前的样本为条件。WaveNet 是一个全卷积神经网络,卷积层具有各种膨胀因子,允许其感受野随深度呈指数增长。输入序列是人类说话者记录的波形。
 DeepMind)
DeepMind)
Tacotron 2 是一种神经网络架构,用于从文本中使用带有注意力的循环序列到序列模型直接进行语音合成。编码器(下图中的蓝色块)将整个文本转换为固定大小的隐藏特征表示。然后,自回归解码器(橙色块)使用此特征表示,一次生成一个频谱图帧。在 NVIDIA Tacotron 2 和 WaveGlow for PyTorch 模型中,自回归 WaveNet(绿色块)由基于流生成的 WaveGlow 所取代。

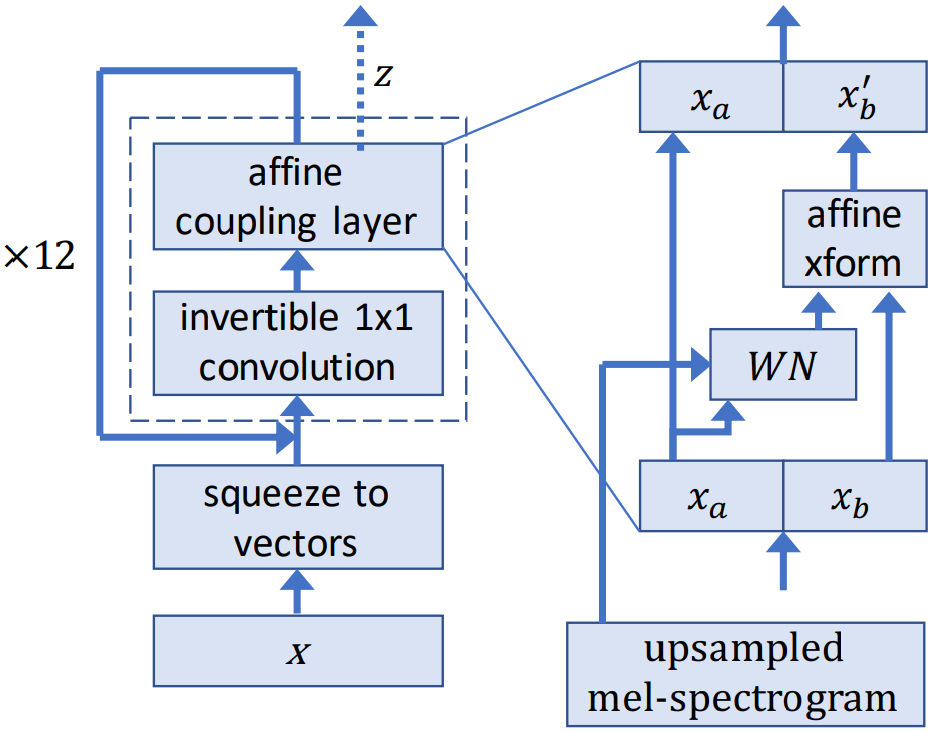
WaveGlow 是一个基于流的模型,它使用梅尔频谱图来生成语音。
在训练过程中,模型通过一系列流程学习将数据集分布转换为球形高斯分布。流的一个步骤包含一个可逆卷积,然后是一个修改后的 WaveNet 架构,该架构用作仿射耦合层。在推理期间,网络为反向网络,音频样本则从高斯分布中生成。
行业应用
医疗健康
医疗健康面临的困难之一是难以获得。打医生办公室电话并一直等待的情况十分常见,与索赔代表联系可能同样困难。通过实施自然语言处理 (NLP) 来训练聊天机器人是医疗健康行业的一项新兴技术,可以解决医疗专业人员的短缺问题,并开创与患者的沟通渠道。
在这篇博客(NGC 中的 NVIDIA Clara Guardian 为智能医院助力)中,您可以了解如何构建虚拟患者助手客户端应用程序,该应用程序用于接收来自患者的输入查询、通过提取意图和相关位置来解释查询,并以自然声音实时计算响应。
金融服务
NLP 是为金融服务公司构建更好的聊天机器人和 AI 助理的关键组成部分。
零售
聊天机器人技术也常用于零售应用程序,能够准确分析客户查询,并生成回复或建议。这可简化客户流程,并提高商店运营效率。
GPU:加速深度学习
Tacotron 2 等近期的创新已将文本转语音技术融入到了深度学习领域。先进的深度学习神经网络可能有数百万乃至十亿以上的参数需要通过反向传播进行调整。此外,它们需要大量的训练数据才能实现较高的准确度,这意味着成千上万乃至数百万的输入样本必须同时进行向前和向后传输。由于神经网络由大量相同的神经元构建而成,因此本质上具有高度并行性。这种并行性会自然映射到 GPU,因此相比仅依赖 CPU 的训练,计算速度会大幅提高。因此,GPU 已成为训练基于神经网络的大型复杂系统的首选平台,推理运算的并行性质也有助于在 GPU 上执行。

NVIDIA GPU 加速文本转语音
借助对话式 AI 部署服务似乎比较困难,但 NVIDIA 现已具备能够简化这一流程的工具,包括神经模块(简称 NeMo)、NVIDIA®TensorRT™ 和一项名为 NVIDIA Riva 的新技术。NGC 中的多个预训练模型可用于 ASR、NLP 和 TTS,例如 BERT、Tacotron2 和 WaveGlow。这些模型使用数千小时的开源和专有数据进行训练,以获得高准确度,并在 NVIDIA DGX™ 系统上训练超过 10 万小时。GPU 加速的 Tacotron2 和 Waveglow 利用 NVIDIA T4 GPU 执行推理的速度比仅使用 CPU 的解决方案快 9 倍。
NVIDIA NeMo 是一个带有 PyTorch 后端的开源工具包,使开发者能够使用三行代码快速构建和训练复杂的、先进的神经网络架构。NeMo 还附带有适用于 ASR、NLP 和 TTS 的可扩展模型集合。这些集合提供了轻松构建先进网络架构(例如 QuartzNet、BERT、Tacotron 2 和 WaveGlow)的方法。借助 NeMo,您还可以使用现有 API 从 NVIDIA NGC 自动下载和实例化这些模型,从而在自定义数据集上微调这些模型。

NVIDIA Riva 是一种应用程序框架,能够为完成对话式 AI 任务提供多个流程。将文本低延迟转换为高质量、自然发音的语音可能是颇具挑战性的任务之一。借助 Riva 文本转语音 (TTS) 流程,对话式 AI 能够在尽可能短的时间内用自然发音的语音做出响应,从而提供沉浸式的用户体验。

NVIDIA GPU 加速的端到端数据科学
NVIDIA RAPIDS™ 软件库套件基于 CUDA-X AI™ 而构建,您可借此在 GPU 上完全自由地执行端到端数据科学和分析流程。此套件依靠 NVIDIA CUDA® 基元进行低级别计算优化,但通过用户友好型 Python 接口能够实现 GPU 并行化和高带宽显存速度。

NVIDIA GPU 加速的深度学习框架
GPU 加速的深度学习框架能够为设计和训练自定义深度神经网络带来灵活性,并为 Python 和 C/C++ 等常用编程语言提供编程接口。MXNet、PyTorch、TensorFlow 等广泛使用的深度学习框架依赖于 NVIDIA GPU 加速库,能够提供高性能的多 GPU 加速训练。

后续步骤
如需了解详情,请参阅以下博客、代码示例和 Jupyter notebook:
- NVIDIA 对话式 AI 和对话式 AI SDK 网页
- 隆重推出 Riva:适用于 GPU 加速对话式 AI 应用程序的框架
- 使用 NVIDIA NeMo 加速语音和语言模型的开发
- 使用 NVIDIA Riva 为文本转语音服务获得超过 60 的实时率
- 实时文本中的一般自然发音语音(博客)
- 如何使用 TensorRT 在 GPU 上部署实时文本转语音应用程序(博客)
- TTS NeMo 代码示例
- NVIDIA Tacotron2 代码示例
- 使用 ForwardTacotron 创建稳健的神经语音合成
- NGC 中的 NVIDIA Clara Guardian 为智能医院助力
了解详情:
- GPU 加速数据中心可以用更少的服务器、更小的地面空间和更低的功耗来提供前所未有的性能。NVIDIA GPU Cloud 免费提供大量软件库,以及用于构建充分利用 GPU 的高性能计算环境的工具。
- NVIDIA 深度学习培训中心提供由导师指导式基本工具和技术实战培训,可用于构建基于 Transformer 的自然语言处理模型,完成文档分类等文本分类任务。
