机器学习 (ML) 采用算法和统计模型,使计算机系统能够在大量数据中找到规律,然后使用可识别这些模式的模型来预测或描述新数据。
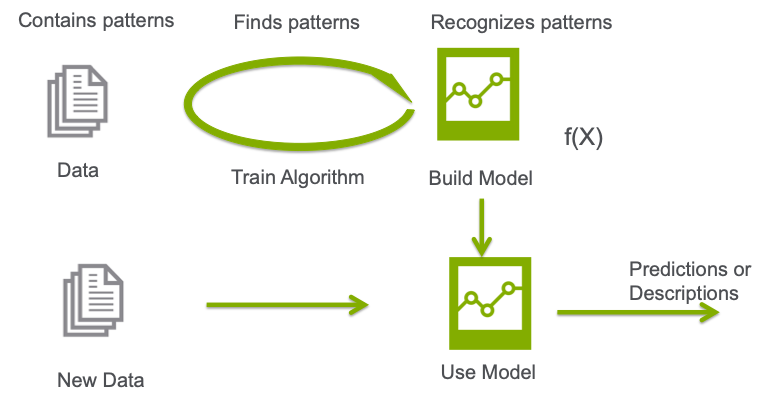
机器学习 (ML) 采用算法和统计模型,使计算机系统能够在大量数据中找到规律,然后使用可识别这些模式的模型来预测或描述新数据。
简而言之,机器学习就是训练机器去学习,而不需要明确编程。机器学习作为 AI 的一个子集,以其最基本的形式使用算法来解析数据、学习数据,然后对现实世界中的某些内容做出预测或判断。

换句话说,机器学习使用算法从输入到机器学习平台的数据中自动创建模型。典型的程序化或基于规则的系统获取程序化规则中的专家知识,但当数据发生变化时,这些规则可能会变得难以更新和维护。机器学习的优势在于,它能够从越来越多输入算法的数据中学习,并且可以给出数据驱动的概率预测。这种在当今大数据应用中快速有效地利用和应用高度复杂算法的能力是一种相对较新的发展。
几乎任何可以用数据定义的模式或一组规则来完成的离散任务都可以通过自动化方式进行,因此使用机器学习可以大大提高效率。这使得公司可以改变以前只有人工才能完成的流程,包括客户服务电话路由以及履历审查等等。
机器学习系统的性能取决于一些算法将数据集转换为模型的能力。不同算法适用于不同问题和任务,而这些问题的解决和任务的完成也取决于输入数据的质量以及计算资源的能力。
机器学习采用两种主要技术,将算法的使用划分为不同类型:监督式、无监督式以及这两种技术的组合。监督式学习算法使用已标记数据,无监督式学习算法在未标记数据中找规律。半监督式学习混合使用已标记和未标记数据。增强学习训练算法,基于反馈更大限度地利用奖励。
监督式机器学习(也称为预测分析)使用算法来训练模型,以在包含标签和特征的数据集中找规律。然后,它使用经过训练的模型预测新数据集的特征标签。

监督式学习可以进一步分为分类和回归。
分类根据已知项目的已标签示例来确定一个项目属于哪个类别。逻辑回归用于根据已知为/非欺诈交易的特征(交易金额、时间以及上次交易地点)来估计信用卡交易为欺诈交易的概率(标签)。

其他分类示例包括:
回归可估算目标结果标签与一个或多个特征变量之间的关系,以预测连续数值。在下面的简单示例中,线性回归用于根据房屋面积(特征)估算房价(标签)。

回归的其他示例包括:
监督式学习算法包括:
无监督式学习(也称为描述性分析)事先未提供已标记数据,因此有助于数据科学家发现先前未知数据规律。这些算法尝试“学习”输入数据中的固有结构,并发现相似性或规律性。常见的无监督式任务包括聚类和关联。
在聚类中,算法通过分析输入示例之间的相似性将输入分为不同类别。聚类的一个示例是,为了更好地定制产品和服务,公司希望对其客户进行细分。客户可以按人口统计数据和购买记录等特征进行分组。为了得到更有价值的结果,通常将无监督式学习聚类与监督式学习聚类相结合。
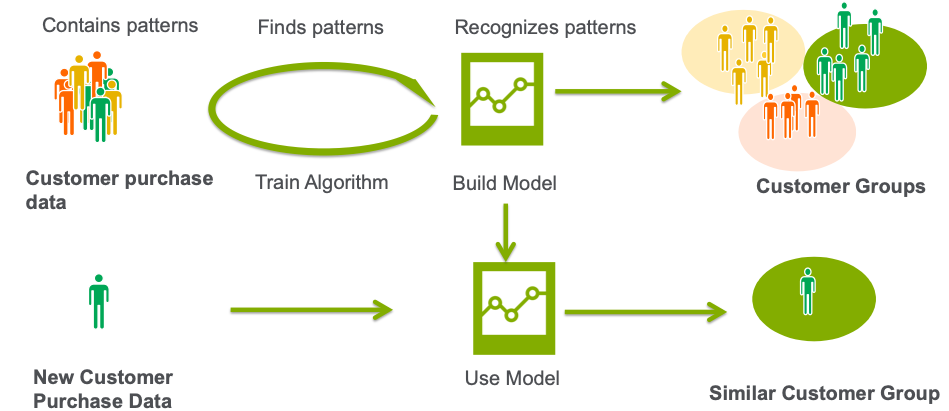
其他聚类示例包括:
关联或频繁模式挖掘可以在大型数据项集合中发现频繁同时发生的关联(关系、依赖关系)。一个同时发生的关联示例是经常一起购买的产品,例如有名的啤酒和纸尿裤。对购物者行为的分析发现,购买纸尿裤的男性通常也会买啤酒。
无监督式学习算法包括:
机器学习对企业的好处是多种多样的,包括:
加速计算和 ML 正推动医疗健康领域的智能计算。NVIDIA Clara™ 提供单一平台,整合医学影像、基因组学、患者监控以及药物研发,并可将该平台部署在嵌入式系统、边缘、每个云端等任何地方,助力医疗健康行业进行创新并加快实现精准医疗的目标。
领先的零售商正利用 ML 来减少损耗、改善预测、实现仓库物流自动化、确定店内促销活动和实时定价、为客户提供个性化服务和建议,以及在实体店和网店提供更出色的购物体验。
了解消费者行为对于零售商而言变得更为重要。为了推动发展,采用智能推荐进行个性化营销。为提高收入,在线零售商使用由 GPU 提供支持的机器学习 (ML) 和深度学习 (DL) 算法来打造更快速、更准确的推荐引擎。购物者的购买以及网络操作历史记录为机器学习模型的分析提供了数据,从而得出建议,并支持零售商在促销方面所作的努力。
金融机构正在采用 ML 来提供更智能、更安全的服务。GPU 驱动的 ML 解决方案可以在大量数据中识别关键见解,通过自动化减轻员工的日常任务负担,加速风险计算和欺诈检测,并借助更准确的推荐系统改善客户服务。
NVIDIA 提供预训练模型和软件解决方案,可大幅简化 ML 应用程序。例如,NVIDIA Metropolis 平台让开发者能够构建 ML 应用程序,以改进零售库存管理、增强损失预防措施,并简化消费者的结账体验。
作为一个实际示例,沃尔玛利用 NVIDIA 的技术来管理员工工作流程,并确保某些商店的肉类和农产品的新鲜度。同样地,宝马采用 NVIDIA 的先进 AI 解决方案,在其制造厂中自动进行光学检查。中国移动运营着超大无线网络,利用 NVIDIA 的平台通过 5G 网络提供 AI 功能。
企业越来越受数据驱动:感知市场和环境数据,并使用分析和机器学习来识别复杂模式、检测变化,并做出直接影响利润的预测。数据驱动型公司使用数据科学来管理和理解海量数据。
数据科学是每个行业的一部分。零售、金融、医疗健康和物流等行业的大型企业利用数据科学技术提高其竞争力、响应速度和效率。广告公司用它更有效地定位广告。按揭贷款公司用它来准确预测默认风险,以获得最大收益。零售商用它来简化供应链。事实上,正是本世纪头中期 Hadoop、NumPy、scikitlearn、Pandas 和 Spark 等开源、大规模数据分析和机器学习软件的出现,引发了这场大数据革命。
如今,数据科学和机器学习已成为全球超大的计算领域。预测机器学习模型的精度即便提升微小,最低也能带来数十亿的价值。预测模型训练是数据科学的核心。事实上,大部分数据科学 IT 预算都用于构建机器学习模型,其中包括数据转换、特征工程、训练、评估和可视化。要构建更好的模型,数据科学家需要通过大量迭代进行训练、评估和再训练。现今,这些迭代可能需要数天时间,这不仅会限制产品部署之前完成的迭代周期数量,还会影响最终结果的质量。
在企业间运行分析和机器学习需要大量的基础设施。《财富》500 强企业扩展计算能力,并投资数千台 CPU 服务器以构建大量数据科学集群。CPU 横向扩展不再有效。每年,全球数据量都会翻倍,而随着摩尔定律的终结,CPU 计算也遭遇了瓶颈。GPU 拥有一个大规模并行架构,当中包含数千个高效小核心,专为同时处理多重任务而设计。类似于科学计算和深度学习如何转向 NVIDIA GPU 加速,数据分析和机器学习也将受益于 GPU 并行化和加速。
NVIDIA 开发了 RAPIDS™,这是一个开源的数据分析和机器学习加速平台,用于完全在 GPU 中执行端到端数据科学训练管线。它依赖于 NVIDIA® CUDA® 基元进行低级别计算优化,但通过用户友好型 Python 界面实现 GPU 并行结构和极高的显存带宽。
RAPIDS 库使用的数据完全存储在 GPU 显存中。这些库以针对分析优化的数据格式(即 Apache Arrow)使用共享 GPU 显存访问数据。这样一来,无需在不同库之间传输数据。它还支持通过 Arrow API 实现与标准数据科学软件和数据提取的互操作性。在高速 GPU 显存上运行完整的数据科学工作流程,以及并行处理 GPU 核心的数据加载、数据操作和 ML 算法,将端到端数据科学工作流程的速度提高 50 倍。
RAPIDS 专注于分析和数据科学的常见数据准备任务,提供了一个熟悉的 DataFrame API,与 scikit-learn 和各种机器学习算法集成,无需支付典型的序列化成本。这可加速端到端流程(从数据准备到机器学习,再到深度学习 (DL))。RAPIDS 还包括对多节点、多 GPU 部署的支持,大大加快了对更大规模数据集的处理和训练。

DataFrame - cuDF – 这是一个基于 Apache Arrow 的 GPU 加速 DataFrame 操作库。它专为实现模型训练的数据管理而设计。核心加速、低级别 CUDA C++ 内核的 Python 绑定反映了 Pandas API,可以从 Pandas 顺利上手过渡。
Machine Learning Libraries - cuML 是一个 GPU 加速的机器学习库集合,最终将提供 scikit-learn 中所有机器学习算法的 GPU 版本。
Graph Analytics Libraries - cuGRAPH 是一个图形分析库集合,可无缝集成到 RAPIDS 数据科学平软件套件
深度学习库 – RAPIDS 提供原生 CUDA array_interface 以及 DLPak 支持。这意味着,Apache Arrow 中存储的数据可以无缝推送到接受 TensorFlow、PyTorch 和 MxNet 等 array_interface 的深度学习框架。
可视化库 – RAPIDS 将包括基于 Apache Arrow 的紧密集成的数据可视化库。原生 GPU 内存数据格式可提供高性能、高 FPS 数据可视化,即使存储非常大的数据集。
随着 ML 和 DL 越来越多地应用于更大的数据集,Spark 已成为一种常用工具,能够在准备机器学习的原始输入数据时执行所需的数据预处理任务。

NVIDIA 与 Apache Spark 社区合作,将 GPU 引入 Spark 的本地处理中。借助 Apache Spark 3.0 和适用于 Apache Spark 的 RAPIDS 加速器,您现在可以在 GPU 支持的集群上实现从提取到数据准备再到模型训练和调试的单个流程,从而消除瓶颈、提高性能并简化集群。

