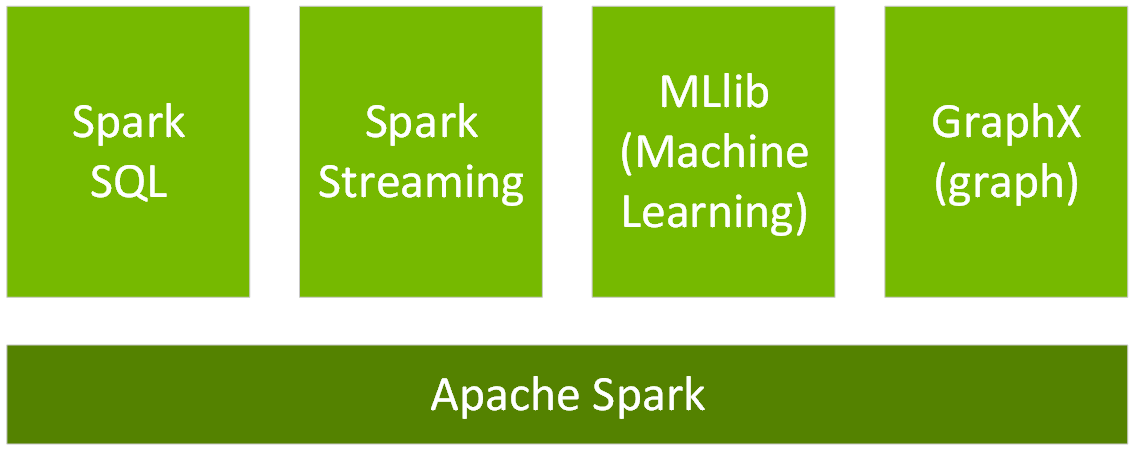
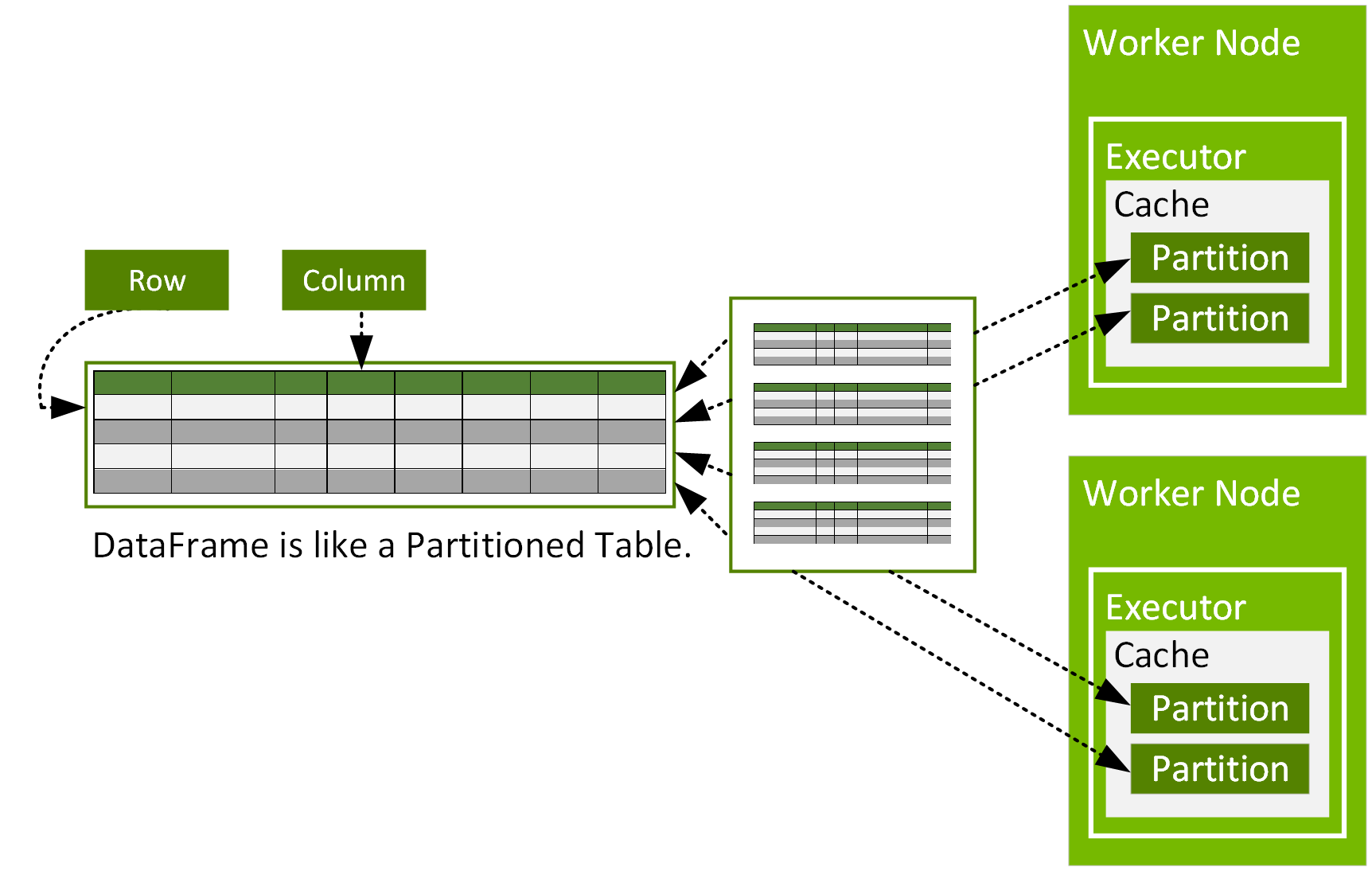
Spark DataFrame 是 org.apache.spark.sql.Row 对象的分布式数据集,跨集群内的多个节点进行分区,并具备并行操作性。DataFrame 表示具有行和列的数据表,类似于由 R 或 Python 语言编写的 DataFrame,但具备 Spark 优化功能。DataFrame 由多个分区组成,每个分区都是数据节点缓存中的一个行范围。
DataFrame 可以从不同数据源(如 csv、parquet、JSON 文件、Hive 表或外部数据库)进行构建。用户可以使用关系转换和 Spark SQL 查询对 DataFrame 进行操作。
Spark shell 或 Spark 笔记本则提供了一种交互式使用 Spark 的简单方式。您可以使用以下命令在本地模式下启动 shell:
$ /[installation path]/bin/spark-shell --master local[2]
随后,您可以将本章其余部分的代码输入 shell,以交互方式查看结果。在代码示例中,shell 的输出以结果开头。
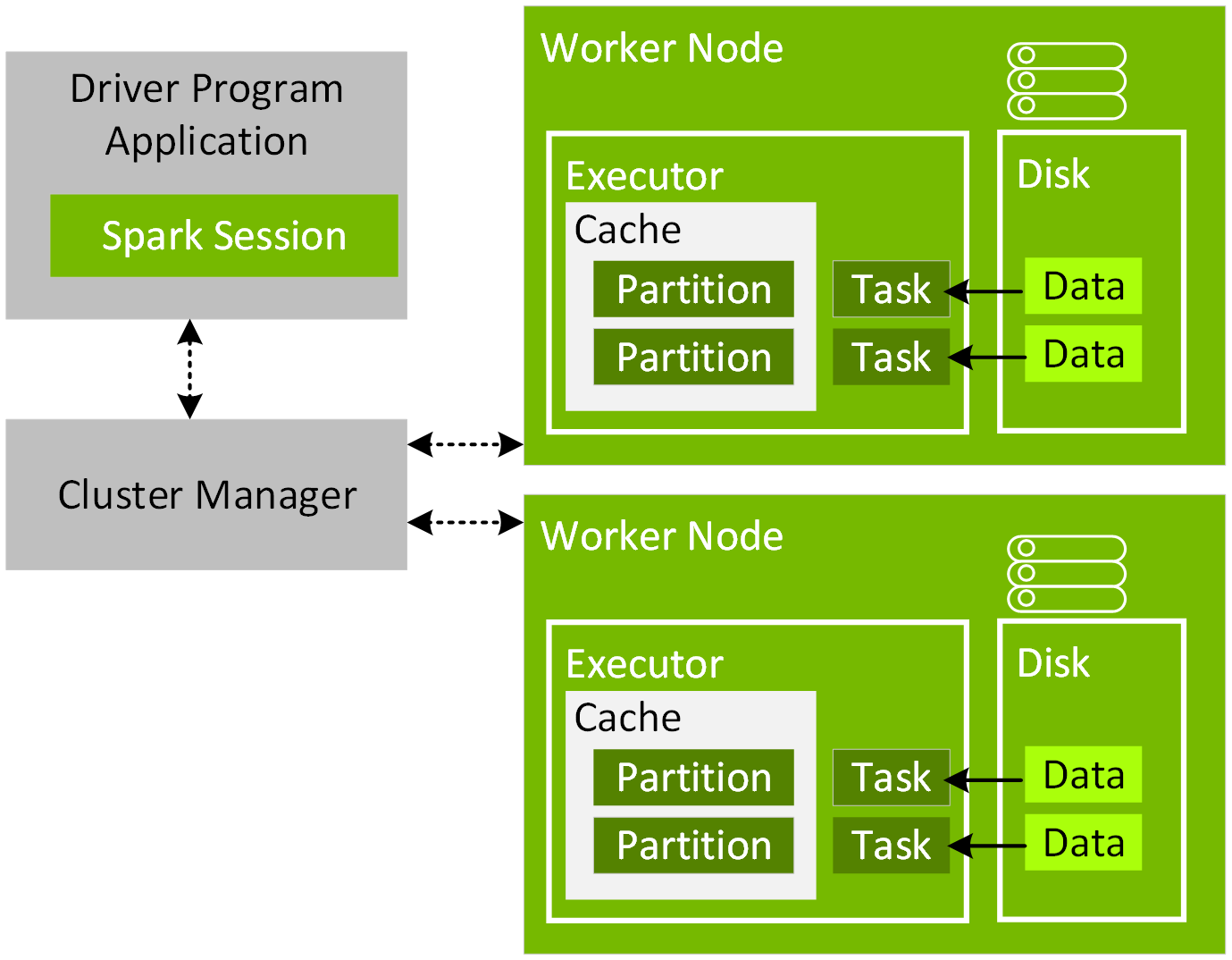
为在应用程序驱动和集群管理器之间协调执行作业,请在程序中创建 SparkSession 对象,具体如以下代码示例所示:
val spark = SparkSession.builder.appName("Simple Application").master("local[2]").getOrCreate()
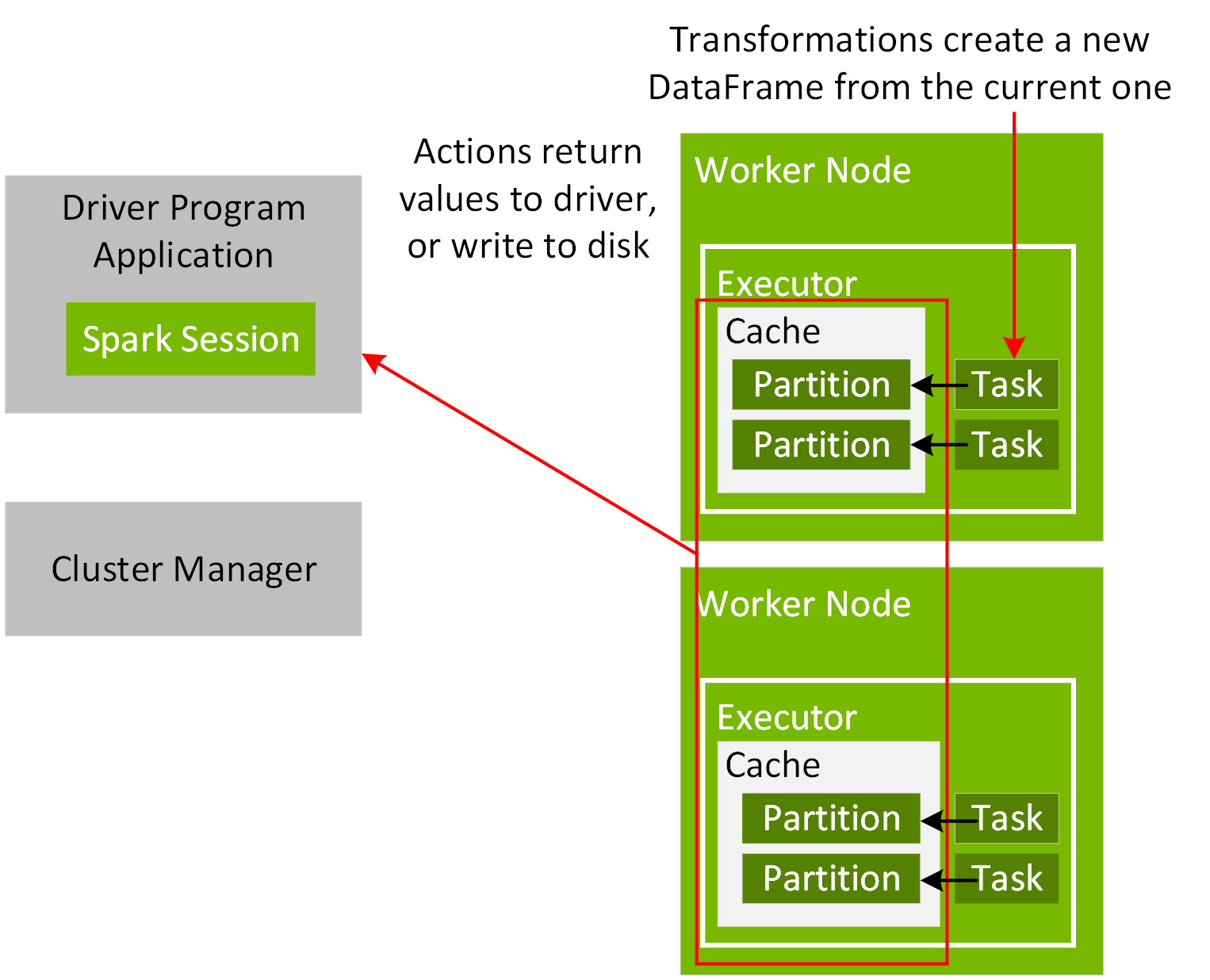
Spark 应用程序启动后,其将通过主 URL 连接到集群管理器。在创建 SparkSession 对象或提交 Spark 应用程序时,可以将主 URL 设置为集群管理器或 local[N],以使用 N 个线程在本地运行。使用 Spark shell 或 Spark 笔记本时,SparkSession 对象已预先创建完毕,并可用作变量 spark。成功连接后,集群管理器将按照为集群内节点进行配置的方式来分配资源并启动执行程序进程。Spark 应用程序执行后,SparkSession 会将任务发送给执行程序以开始运行。
借助 SparkSession 读取方法,您可将文件中的数据读取到 DataFrame 中,以指定模式的文件类型、文件路径和输入选项。
import org.apache.spark.sql.types._
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
val schema =
StructType(Array(
StructField("vendor_id", DoubleType),
StructField("passenger_count", DoubleType),
StructField("trip_distance", DoubleType),
StructField("pickup_longitude", DoubleType),
StructField("pickup_latitude", DoubleType),
StructField("rate_code", DoubleType),
StructField("store_and_fwd", DoubleType),
StructField("dropoff_longitude", DoubleType),
StructField("dropoff_latitude", DoubleType),
StructField("fare_amount", DoubleType),
StructField("hour", DoubleType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", DoubleType),
StructField("day_of_week", DoubleType),
StructField("is_weekend", DoubleType)
))
val file = "/data/taxi_small.csv"
val df = spark.read.option("inferSchema", "false")
.option("header", true).schema(schema).csv(file)
result:
df: org.apache.spark.sql.DataFrame = [vendor_id: double, passenger_count:
double ... 14 more fields]
take 方法返回一个数组,其中包含此 DataFrame 中的对象,在本文示例中即为 org.apache.spark.sql.Row 类型的数组。
df.take(1)
result:
Array[org.apache.spark.sql.Row] =
Array([4.52563162E8,5.0,2.72,-73.948132,40.829826999999995,-6.77418915E8,-1.0,-73.969648,40.797472000000006,11.5,10.0,2012,11,13.0,6.0,1.0])